Modèle Sage 100
Utilisez les liens suivants pour accéder à une section :
Introduction
L'installation des Modèles vous fournit un ensemble de Vues, de Tableaux de Bord et de Rapports prêts à l'emploi.
L'installation (en supposant que le Central Point soit fraîchement installé et vide), se fera en deux étapes :
- Configuration des Sources de Données pour les bases de données ERP et Entrepôt de Données (facultatif).
- Importation des modèles dans le point central.
Il peut y avoir d'autres étapes, y compris la construction et le chargement des Cubes OLAP.
Data Sync de Nectari
Data Sync est nécessaire pour Sage 100
Il est également recommandé de le faire si vous ne souhaitez pas interroger la base de données ERP qui utilise les Données de Production, et que vous préférez interroger la copie de cette base de données.
Pour Sage 100 Standard, vous devez utiliser Data Sync pour effectuer une consolidation ou une synchronisation des données.
Prérequis
- Une version de Sage 100 prise en charge par Sage
- Une base de données de destination (de préférence, dans la même collation que votre base de données Sage 100 )
- Une version valide du Data Sync (voir Installer Data Sync pour plus d'informations)
Paramétrer les Connexions
Chaque base de données que vous souhaitez consolider nécessite deux Connexions Source :
- Une avec le Type de Suivi défini sur Date
- Une avec le Type de Suivi défini sur Aucun
Malheureusement, toutes les Tables de Sage 100 ne contiennent pas les champs DateUpdated et TimeUpdated, et pour cette raison, certaines Tables ne peuvent être chargées de manière incrémentielle. Heureusement, ces Tables sont souvent très petites et ne posent pas de problème.
- Le Fuseau Horaire doit être réglé sur l'heure du serveur d'application Sage 100 .
Paramètres pour Sage 100 Premium
Si vous utilisez Sage 100 Premium, procédez comme suit. Si ce n'est pas le cas, reportez-vous à Paramètres pour Sage 100 Standard.
- Suivez la procédure décrite dans Ajouter une Connexion Source et Destination pour créer une connexion Source et une connexion de Destination.
Vous devriez obtenir un résultat similaire à ceci pour la connexion Source :
Vous devriez obtenir un résultat similaire à ceci pour la connexion de Destination :
Paramètres pour Sage 100 Standard
- Dans Data Sync, cliquez sur la tuile Connexions.
- Dans le coin supérieur gauche, cliquez sur Nouveau pour créer une nouvelle connexion Source .

- Dans la liste, sélectionnez ODBC.

Panneau Propriétés de la Connexion
- Dans le champ Description, entrez un nom pour cette connexion.
- Laissez les champs Expression Nulle sur leurs valeurs par défaut.
- Entrez un guillemet simple dans les champs Délimiteur de la Chaîne Constante.
- Dans la section ci-dessous, cochez toutes les cases à l'exception des cases Prise en charge des schémas et Prise en charge des sous-requêtes.
Lorsque l'on ajoute une Requête SQL au lieu de synchroniser directement une Table, le fait de décocher la case Prise en charge des sous-requêtes avant de sauvegarder crée plusieurs limitations. Après avoir importé le modèle d'extraction, ne vous reportez à la section Ajouter une Requête SQL avec un Connecteur ODBC sans Sous-Requête que si vous souhaitez ajouter une requête SQL.
- Lorsque vous cochez la case Prise en charge des Guillemets, ne cochez que les cases Alias et Colonnes.
- Entrez un guillemet simple dans les champs Délimiteur Gauche et Délimiteur Droit.
- Laissez les autres Champs sur leurs valeurs par défaut.
- Dans la liste déroulante Chargement des Métadonnées, sélectionnez À partir de l'instruction SELECT.


Panneau Autres Propriétés de la Connexion
- Cliquez sur Ajouter une propriété pour ajouter les propriétés décrites dans le tableau ci-dessous :
| Propriété | Valeur | Exemple |
|---|---|---|
| Driver | {MAS 90 4.0 ODBC Driver} | |
| UID | [Nom d'utilisateur Sage 100] | |
| PWD | [Mot de passe Sage 100] | |
| Directory | [Chemin Sage MAS90] | \\[Serveur]\Sage\Sage 100 Advanced\MAS90 |
| Prefix | [Chemin Sage MAS90]\SY | \\[Serveur]\Sage\Sage 100 Advanced\MAS90\SY |
| ViewDLL | [Chemin Sage MAS90]\Home | \\[Serveur]\Sage\Sage 100 Advanced\MAS90\Home |
| Company | [Code Société] | ABC |
| LogFile | \PVXODBC.LOG | |
| CacheSize | 4 | |
| DirtyReads | 1 | |
| BurstMode | 1 | |
| StripTrailingSpaces | 1 | |
| SERVER | NotTheServer |
Pour plus d'informations sur ces paramètres, cliquez ici.
Panneau Paramètres Avancés
- Dans la liste déroulante Type de Suivi, sélectionnez Date.
- Réglez le fuseau horaire sur l'heure du serveur d'application Sage 100.
Vous devriez obtenir un résultat similaire à celui-ci :
- Cliquez sur Enregistrer pour terminer.
Importer les Extractions
Cette fonction vous permet d'importer un modèle prédéfini ou de restaurer une sauvegarde que vous avez effectuée vous-même avec la fonction Exporter (voir Exporter une Extraction pour plus de détails).
Certains modèles prédéfinis sont déjà disponibles ; si vous n'y avez pas accès, veuillez contacter votre partenaire. Un exemple de modèle prédéfini que vous pourriez utiliser est celui qui définit la liste des tables et des champs à synchroniser pour envoyer des données Sage 300, X3, Acumatica, Salesforce vers le Cloud.
Une Extraction par connexion Source créée est nécessaire pour récupérer correctement les données.
- Cliquez sur l'une des extractions de la liste puis sur l'icône Importer une extraction située dans le coin supérieur droit.

- Dans la fenêtre Importer une Extraction, cliquez sur l'hyperlien Choisissez un fichier zip pour naviguer jusqu'à l'emplacement où vous avez enregistré le fichier d'exportation.zip ou faites-le glisser directement dans cette fenêtre et cliquez sur Suivant.

Pour Sage 100, quatre fichiers zip seront fournis.
- Si vous effectuez une consolidation, importez le fichier DS_EXTR_[Version-Logiciel]_[Version-Extraction]_Sage 100 with refresh DS-CONSO.zip.
- Si vous n'avez qu'une seule Compagnie et que vous souhaitez reproduire la base de données, importez le fichier DS_EXTR_[Version-Logiciel]_[Version-Extraction]_Sage 100 with refresh DS-SYNC.zip pour effectuer une synchronisation.
- Dans le volet de gauche, sélectionnez le type d'extraction que vous souhaitez effectuer et cliquez sur Suivant.


Pour Sage 100, il est nécessaire d'utiliser CPYID pour le Nom de Colonne et les codes de la Société pour le champ Identifiant Unique.
- Référez-vous à Configurer le Panneau Extraction pour définir l'extraction et cliquez sur Importer pour terminer le processus.


- Vous devriez obtenir un résultat similaire à celui-ci :

Le diagramme ci-dessous illustre la manière dont Data Sync traite les données.
La fenêtre Extractions passera automatiquement à la fenêtre Tables.
Référez-vous Ajouter une Requête SQL si vous souhaitez ajouter des instructions SQL à certaines tables et Configurer les Champs pour personnaliser les champs (ajouter un calcul, changer le nom de la destination, etc.)
Ajouter une Requête SQL avec un Connecteur ODBC sans Sous-Requête
Lorsque les Sous-Requêtes sur votre connexion Source pour ODBC sont désactivées, Data Sync de Nectari n'analyse plus votre code avec les paramètres et exécute uniquement le code brut saisi dans la fenêtre Requête SQL. Notez que les ERPs tels que Sage 100
Pour plus d'informations sur Sage 100
Lorsque vous ajoutez une Requête SQL (voir Configurer les Champs), il vous faudra tenir compte de plusieurs aspects :
- Si les Délimiteurs sont absolument nécessaires avec votre Pilote ODBC, vous devrez les définir.
- Pour faire une Jointure, vos Tables doivent être placées à l'intérieur de {oj [...]}.
SELECT Customer.*
FROM {oj Customer INNER JOIN SalesReps ON Customer.SALESREP = SalesReps.SALESREP}
- Vous ne pouvez pas utiliser * (astérisque) sans Alias dans votre instruction SELECT si votre instruction SELECT joint plus d'une table. Bien que cela ne vous donne pas forcément une erreur, il y a un risque d'introduire des erreurs lorsque vous avez plusieurs Colonnes possédant le même nom dans différentes Tables .
Voici un exemple d'une instruction qui provoquerait des erreurs :
SELECT *
FROM {oj Customer INNER JOIN SalesReps ON Customer.SALESREP = SalesReps.SALESREP}
- Vous ne pouvez pas utiliser plusieurs * (astérisque) avec un Alias dans votre instruction SELECT. Ce problème s'applique également aux multiples Colonnes portant le même nom, bien que cela se casse simplement lors de l'exécution de la tâche Traitement des Enregistrements Supprimés, car il ne sera pas possible de trouver de quelle Table provient le Champ.
Voici un exemple d'une instruction qui provoquerait des erreurs :
SELECT Customer.*, SalesReps.*
FROM {oj Customer INNER JOIN SalesReps ON Customer.SALESREP = SalesReps.SALESREP}- Évitez de créer des Champs Calculés dans l'instruction SELECT. Utilisez plutôt les options du menu de la section Champ (voir Configurer les Champs). Dans la plupart des cas, cela ne posera pas de problème. Toutefois, lors de la définition de ce Champ en tant que Clé primaire ou Clé de Suivi, vous risquez d'introduire une erreur lors de l'exécution des tâches Charge Incrémentale ou Traitement des Enregistrements Supprimés.
Si vous souhaitez utiliser les Fonctions, ODBC ne prend pas en charge les fonctions T-SQL ou PL/SQL. Vous devez utiliser les fonctions ODBC dont dispose le pilote. Veuillez consulter la Documentation de Microsoft pour plus de détails concernant ces Fonctions.
Ajouter une Table non incluse dans le fichier zip de l'Extraction
- Reportez-vous à Configurer les Champs pour utiliser le Champ Calculé suivant comme Clé de Suivi pour la tâche Charge Incrémentale si vous souhaitez ajouter une table :
La table (ou l'une des tables si vous avez fait une Jointure pour les obtenir d'une autre table) doit contenir les champs DateUpdated et TimeUpdated.
{fn TIMESTAMPADD(SQL_TSI_SECOND,
{fn CONVERT( {fn FLOOR( {fn CONVERT(TimeUpdated,SQL_FLOAT)} * 3600 ) } - {fn CONVERT( {fn FLOOR( {fn CONVERT(TimeUpdated,SQL_FLOAT)} ) }, SQL_INTEGER) } *3600, SQL_INTEGER) },
{fn TIMESTAMPADD(SQL_TSI_HOUR, {fn CONVERT( {fn FLOOR( {fn CONVERT(TimeUpdated,SQL_FLOAT)} ) }, SQL_INTEGER) } ,{fn CONVERT(DateUpdated,SQL_TIMESTAMP)} )} )}
Valider et Construire les Extractions
Une fois que votre extraction (source, connexion de destination et leurs tables associées) est configurée, l'étape suivante consiste à valider le paramétrage d'une extraction, avant de pouvoir l'exécuter.
La fonction :
- S'assurera que toutes les tables/champs existent bien dans les connexions sources,
- Validera toutes les requêtes SQL ou les champs calculés,
- S'Assurera que l'intégrité des données dans la connexion de destination n'est pas affectée (ex : modification de la structure de la table).
Pour ce faire :
- Sélectionnez l'extraction que vous souhaitez valider et construire dans la liste et cliquez sur l'icône Valider et Construire.

- Dans la nouvelle fenêtre, choisissez l'action qui correspond le mieux à vos besoins et cliquez sur Construire (Valider pour les extractions de type Migration et Exportation).

Le choix sera différent en fonction du type d'extraction que vous sélectionnez.
Pour les extractions de type Synchronisation / Consolidation :
Pour les extractions de type Migration et Exportation :

- Attendez que le processus soit terminé.
Une fenêtre Rapport de Validation apparaîtra pour vous donner un bref aperçu du processus une fois qu'il sera terminé. Les résultats sont affichés dans la colonne Statut et s'il y a une erreur, vous obtiendrez plus de détails en cliquant sur l'hyperlien dans la colonne Erreur qui mène à Page des Journaux.
Lancer les Extractions
Une fois vos données validées (voir Valider et Construire une Extraction pour plus de détails), vous pouvez lancer manuellement l'extraction si vous voulez un résultat immédiat au lieu de la planifier.
- Sélectionnez l'extraction que vous souhaitez exécuter dans la liste et cliquez sur l'icône Lancer l'Extraction Maintenant.

- Dans le coin supérieur droit, choisissez l'action que vous voulez exécuter et le(s) table(s) puis cliquez sur Exécuter.


Charger (uniquement pour une extraction de type Migration) : Charge toutes les données de votre destination à partir de votre source.
Tronquer et Charger : Remplace toutes les données de votre destination par les données actuelles de votre source.
Charge Incrémentale : Récupère uniquement les enregistrements qui ont changé depuis votre dernière Charge Incrémentale et remplacez les enregistrements correspondants dans votre destination par ceux qui ont été mis à jour.
Traitement des Enregistrements Supprimés : Nombre maximal de jours pendant lesquels le processus de validation vérifie si des enregistrements ont été supprimés en fonction de la date de la dernière modification. c.-à-d. Si la valeur est définie à 30 jours, le système vérifiera toutes les transactions qui ont été créées ou mises à jour au cours des 30 derniers jours et validera ensuite si elles existent toujours dans la source. Si elles n'existent plus dans la source, elles seront alors supprimées de la destination.
- Attendez que le processus soit terminé.
Lorsque le processus est terminé, les résultats sont affichés dans la colonne Statut. En cas d'erreur, vous pouvez obtenir plus de détails en cliquant sur l'hyperlien dans la colonne Erreur, qui mène à Page des Journaux.
Configuration de la Sources de Données
Environnements et sources de données
La description donnée à une Source de Données créée pour la première fois est utilisée dans tous les environnements pour décrire cette Source de Données.
Donnez une description générique pour la première fois (par exemple, Source de Données ERP, Source de Données Cube) et, si nécessaire, renommez-la après la création du premier environnement.
Les informations suivantes sont nécessaires pour configurer les Sources de Données :
- Identifiants du serveur de base de données :Nom du serveur, Instance, Stratégie d'authentification.
- Principales informations de la base de données ERP :Nom de la base de données et du schéma.
Source des données ERP
- Dans le coin supérieur droit, cliquez sur le bouton
 pour accéder à la section Administration.
pour accéder à la section Administration.
- Dans le volet de gauche, sélectionnez Env. & Sources de Données.
- Par défaut, il existe déjà un environnement appelé Production, que vous pouvez renommer en double-cliquant dans la zone de texte. Une fois la modification effectuée, appuyez sur la touche Entrée.

- Dans la section Sources de données, cliquez sur
 Ajouter pour créer la première source de données.
Ajouter pour créer la première source de données.
- Terminer la configuration de la source de données ERP. Voir les instructions pour MS SQL Server ci-dessous.



- Description de la source de données :
- Si vous utilisez Data Sync :
- Sage 100 DATASYNC
- Si vous n'utilisez pas Data Sync :
- Sage 100 VIEWS
- Pour le modèle UDM :
- Sage 100 TABLES
- Type :
- SQLSERVER
- Serveur :
- Serveur de base de données de base de données de Sage 100
- Nom de la base de données :
- Nom de la Sage 100base de données de synchronisation (attention à la casse)
- Nom du schéma de base de données :
- Créez les deux entrées suivantes en cliquant sur l'icône (remplacez DatabaseName par la valeur appropriée) :
- Si vous utilisez Data Sync :
-
- DatabaseName.SchémaDestinationDansDataSync
- DatabaseName.NEC_CUSTOM_SCHEMA
- Si vous n'utilisez pas Data Sync :
-
- DatabaseName.NEC_CUSTOM_SCHEMA
- DatabaseName.dbo
- Pour le modèle UDM :
-
- DatabaseName.dbo
- DatabaseName.NEC_CUSTOM_SCHEMA
-
Note
Cette seconde ligne contient le Schéma Nectari Personnalisé.
Vous pouvez en utiliser un autre, mais nous vous recommandons fortement de suivre cette convention d'appellation :
- Commencez par NEC
- Utilisez des majuscules
- Séparez les mots par un trait de soulignement
ImportantChoisissez un nom de Schéma Personnalisé unique pour chaque Environnement.
- Nectarischéma :
- Saisissez le schéma Nectaripersonnalisé choisi pour l'environnement actuel.
- Stratégie d'authentification :
- UtilisationSpécifique
- Nom d'utilisateur :
- Utilisateur SQL accédant à laSage 100 base de données de synchronisation. Par exemple, sa.
- Mot de passe :
- Le mot de passe de l'utilisateur.
- Cliquez sur Valider puis sur Enregistrer pour terminer la configuration de la Source de Données.
Source de Données du Cube
Dans le même Environnement que la Source de Données ERP, créez une nouvelle Source de Données pour le Cube OLAP.
Complétez la définition de la source de données avec toutes les informations appropriées.
La capture d'écran ci-dessous en donne un exemple.
- Serveur :
- Serveur de base de données sur lequel est installé le paquet d'installation Nectari OLAP For SQL Server.
- Nom de la base de données :
- NectariCube.
- Nom du schéma de base de données :
- NectariCube.NEC_FOLDER (remplacer FOLDER par le nom du dossier).
- Où NEC_FOLDER (remplacez FOLDER par le nom du dossier) est le schéma utilisé dans la Base de Données ERP du même environnement.
- Nectarischéma :
- Saisissez le schéma personnalisé choisi pour l'environnement actuel.
- Cliquez sur Valider puis sur Enregistrer.
- Cliquez sur Définir comme entrepôt de données pour définir la source de données comme entrepôt de données, puis entrez les informations suivantes :
- Schéma d'entrepôt de base de données :
- Saisissez à nouveau le schéma Nectari personnalisé que vous avez choisi.
- Utilisez MARS pendant le chargement des cubes :
- Non contrôlé
- Cliquez sur Valider puis sur Enregistrer.
Reportez-vous à Environments and Data Sources pour plus de détails sur l'option MARS.
Importer des Modèles
Pour chaque environnement, les informations suivantes, précédemment configurées, seront requises :
- Nom de la base de données ERP
- Nectari Schéma personnalisé
- Schéma ERP
Téléchargez le fichier du Modèle : TPL_9.X.XXX_Sage100Conso.zip.
Le X représente le numéro de construction du modèle (utilisez le plus haut disponible).
Démarrer l'Importation d'un Modèle
- Dans le coin supérieur droit, cliquez sur pour accéder à la section Administration.
- Dans la section Administration, cliquez sur le menu déroulant
 Modèles dans le volet de gauche.
Modèles dans le volet de gauche. - Sélectionnez
 Importer un modèle.
Importer un modèle. - Choisissez l'emplacement spécifique où les nouveaux modèles seront installés et cliquez sur Suivant.
 Note
NoteHabituellement, le dossier Racine est utilisé.

- Dans la fenêtre Importer un Modèle, cliquez sur Sélectionner les fichiers...

- Trouvez le dossier où vous avez enregistré le fichier Template.zip afin de le sélectionner puis cliquez sur Ouvrir.
- Dans l'écran Mappage des Sources de Données, associez les Sources de Données (ERP) listées dans la colonne Description des Sources de Données Reçues (celles du modèle) aux Sources de Données que vous avez définies précédemment dans le Central Point (listées dans la colonne Description des Sources de Données Actuelles).
- Dans la colonne Description des Sources de Données Reçues, assurez-vous que seules les cases Sources de Données que vous souhaitez utiliser à partir du modèle sont cochées.
- Dans la colonne Description des sources de données actuelles, cliquez sur Lier une source de données pour accéder à la liste déroulante contenant les sources de données existantes et cliquez sur Suivant.

Dans l'écran suivant, l'intégralité du contenu des Modèles est affichée, par rapport à ce que le Central Point utilise déjà.
Par défaut, lors de la première installation, tout sera défini sur Ajouter (laisser tel quel).
- Dans le cas d'une première installation, les quatre premières colonnes afficheront Aucune et Jamais installé, les trois suivantes détailleront le contenu du modèle, et les trois dernières vous donneront le choix d' Ajouter, Mettre à jour ou Sauter pendant l'installation.Note
Dans le cas d'une mise à jour, vous pouvez vous référer à Mettre à jour un Modèle pour plus de détails.
- Cliquez sur Suivant (cela peut prendre du temps).


- Une fois cette opération terminée, une fenêtre vous demandera d'entrer les paramètres nécessaires à la création des objets personnalisés.
- Si plus d'un Environnement a été créé, vous verrez une colonne par Environnement. Vous pouvez décocher une case Environnement, auquel cas les Scripts Globaux ne s'exécuteront pas.
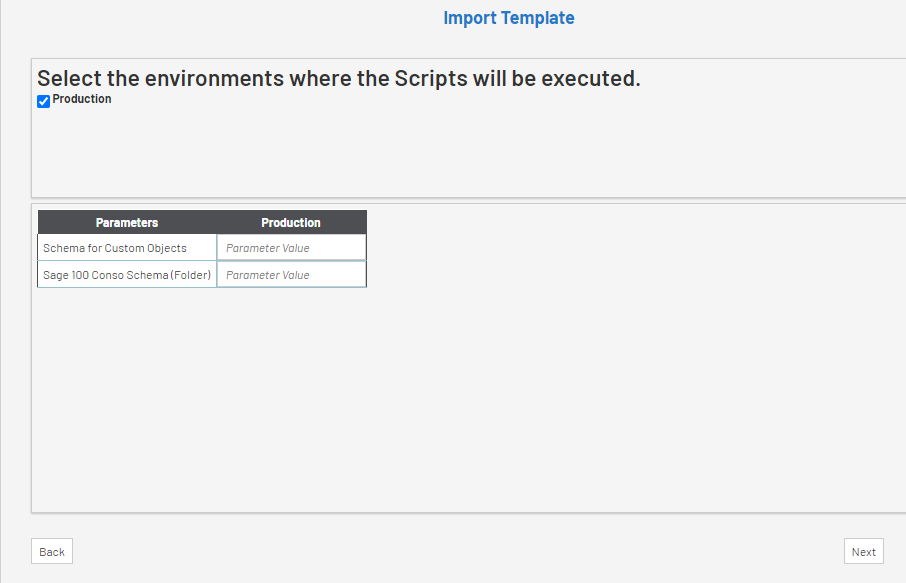
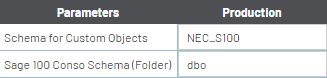
- Complétez les paramètres, voir les exemples ci-dessous, et cliquez sur Suivant.
- Après l'importation, un Rapport d'Exécution sera produit, comme indiqué ci-dessous.Note
La première section concerne la Source de Données ERP et la suivante la Source de Données Cube.
Vous pouvez cliquer sur le bouton
 pour voir les détails de chaque script individuellement. Si aucune panne n'est signalée, fermez la fenêtre.
pour voir les détails de chaque script individuellement. Si aucune panne n'est signalée, fermez la fenêtre.

- Si l'un des scripts ne s'exécute pas, une icône d'échec
 s'affiche. Cliquez sur le symbole d'échec pour afficher la fenêtre Aperçu du Rapport, qui affiche le script SQL correspondant.
s'affiche. Cliquez sur le symbole d'échec pour afficher la fenêtre Aperçu du Rapport, qui affiche le script SQL correspondant.
- Copiez ce script, déboguez, et exécutez le séparément si nécessaire. Les utilisateurs qui maîtrisent SQL peuvent le déboguer directement dans la fenêtre Aperçu du Rapport et l'exécuter en cliquant sur le bouton Essayer de le ré-exécuter.


Mettre à jour un Modèle
Quelques considérations dont vous devez tenir compte avant de commencer :
- Faire de nouvelles sauvegardes de la base de données Nectari et du Central Point est fortement recommandé avant de faire la mise à jour du modèle.
- Vérifier les Modèles de Données de Nectari et les Objets SQL Personnalisés de Nectari qui peuvent avoir été livrés avec la version initiale du modèle, car vous pourriez perdre ces personnalisations lors de la mise à jour.
- Vous devez disposer d'une version de modèle correspondant à la version du logiciel installée. Si vous utilisez Nectari dans sa version 9, le modèle doit également être à la version 9.
Lors d'une mise à jour du logiciel Nectari, seule la version du logiciel est mise à jour, et non le modèle. En d'autres termes, les Modèles de Données et les Vues Nectari existants ne seront pas affectés.
Après une mise à jour du logiciel, il n'est pas obligatoire d'effectuer systématiquement une mise à jour du modèle. Une mise à jour du modèle est utile si vous avez rencontré des problèmes avec des Modèles de Données Nectari spécifiques ou des objets SQL personnalisés Nectari car elle inclut des correctifs.
Pour mettre à jour un modèle :
- Après avoir mappé les Sources de données, cochez les cases des objets que vous souhaitez mettre à jour et cliquez sur Suivant.
 Note
NotePar défaut, aucune case à cocher dans la colonne Mise à jour ne sera cochée. S'il y a un nouveau Modèle de Données ou une nouvelle Vue, la case Ajouter sera cochée. Sélectionnez Sauter si vous voulez l'ignorer.
ImportantSi vous cochez la case Mettre à jour, il écrasera les objets Nectari existants associés à ce modèle de données ou connectés aux autres (dépendances). Veuillez noter que si des personnalisations ont été faites, elles seront perdues.

- Sélectionnez l'environnement dans lequel les scripts seront exécutés et cliquez sur Suivant.
- Complétez les paramètres et cliquez sur Suivant.
- Dans la fenêtre Rapport d'exécution, si l'un des scripts ne s'exécute pas, une icône d'échec s'affiche. Cliquez sur le symbole d'échec pour afficher la fenêtreAperçu du Rapport, qui affiche le script SQL correspondant.
- Copiez ce script, déboguez, et exécutez le séparément si nécessaire. Les utilisateurs qui maîtrisent SQL peuvent le déboguer directement dans la fenêtre Aperçu du Rapport et l'exécuter en cliquant sur le bouton Essayer de le ré-exécuter.
Construire et Charger les Cubes OLAP
Pour créer la structure de la base de données Cubes dans la base Nectaride données Cube précédemment installée, vous devez Construire le Cube.
- Dans le coin supérieur droit, cliquez sur pour accéder à la section Administration.
- Dans le volet de gauche, cliquez sur
 OLAP Manager.
OLAP Manager. - Dans le volet de droite, cliquez sur
 Gérer.
Gérer.
- Dans la section de gauche, sélectionnez tous les cubes à construire en cochant la case à côté de la colonne Description.
- Dans la fenêtre Gérer, sélectionnez Construire dans la liste déroulante Action puis le(s) environnement(s) et cliquez sur Confirmer.

- Dans la fenêtre Confirmation, cochez la case et cliquez sur Oui.

- En cas d'erreur, reportez-vous à Logs pour activer la fonction d'enregistrement.



Maintenant que les cubes sont construits, vous pouvez les remplir.
- Dans le volet de droite, cliquez sur Gérer.
- Dans la section de gauche, sélectionnez tous les cubes à charger en cochant la case à côté de la colonne Description.
- Dans la fenêtre Gérer, sélectionnez Charger tout dans la liste déroulante Action puis le(s) environnement(s) et cliquez sur Confirmer.

- Dans la fenêtre Confirmation, cochez la case et cliquez sur Oui.

L'installation du modèle est maintenant terminée.
Il est maintenant possible de programmer des rafraîchissements de données réguliers pour les Cubes. Pour plus de détails sur la manière de procéder, voir Planificateur.
Remplir les Codes Postaux
Lors de l'importation, une table est créée dans le Schéma Nectari Personnalisé pour les codes postaux.
Bien que la Table ZIP ne soit pas nécessaire pour que le modèle Sage 100 fonctionne, il est recommandé de télécharger et de remplir la Table ZIP avec un transfert de données récent des codes postaux, y compris les détails (latitude, longitude).
Les Navigateurs Web ont mis à jour leur politique concernant les Cookies et ces changements doivent être appliqués à votre Client Web si vous souhaitez intégrer Nectari à votre site ERP, ou utiliser l'Authentification Unique (SSO). Reportez-vous à Gestion des Cookies pour plus de détails.