Sage 100 Template
Use the following links to jump to a section:
Introduction
The Templates installation provides you with a ready-to-use set of Views, Dashboards and Reports.
The installation (assuming the Central Point is freshly installed and empty), will consist of two steps:
- Configuring the Data Sources for the ERP and Data Warehouse (optional) databases.
- Importing the Templates into the Central Point.
There may be other steps including building and loading the OLAP Cubes.
Nectari Data Sync
Data Sync is required for Sage 100
Doing this is also recommended if you do not want to query the ERP database that uses Live Data, and would rather query the copy of this database.
For Sage 100 Standard, you must use Data Sync to perform a consolidation or a synchronization of the data.
Prerequisites
- A version of Sage 100 supported by Sage
- A destination database (preferably, in the same collation as your Sage 100 Database)
- A valid version of Data Sync (refer to Installing Data Sync for more information)
Set the Connections
Each database you want to consolidate needs two Source Connections:
- One with the Tracking Type set to Date
- One with the Tracking Type set to None
Unfortunately, not all Sage 100 Tables contain the DateUpdated and TimeUpdated fields, and for this reason, some Tables cannot be loaded incrementally. Fortunately, these Tables are often very small and do not pose a problem.
- Time Zone has to be set to the Sage 100 Application Server Time.
Settings for Sage 100 Premium
If you are using Sage 100 Premium, do as follows. If not, refer to Settings for Sage 100 Standard.
- Follow the procedure described in Add a Source and Destination Connection to create a Source and a Destination connection.
You should have a result similar to this for the Source connection:
You should have a result similar to this for the Destination connection:
Settings for Sage 100 Standard
- In Data Sync, click on the Connections tile.
- In the upper left corner, click on New to create a new Source connection.

- In the list, select the ODBC.

Connection Properties Panel
- In the Description field, enter a name for this connection.
- Leave the Null Expression fields on their default values.
- Enter a single quote in the String Constant fields.
- In the section below, tick all the checkboxes except the Supports Schemas and Supports Subqueriesand checkboxes.
When adding an SQL Query instead of syncing a Table directly, unticking the Supports Subqueries checkbox before saving creates several limitations. After having imported the extraction template, refer to Add SQL Query with ODBC connector without Subqueries only if you want to add an SQL query.
- When ticking the Supports Quotes checkbox, tick only the Alias and Columns checkboxes.
- Enter a single quote in the Left Delimiter and Right Delimiter fields.
- Leave the other Fields on their default values.
- In the Meta Loading drop-down list, select From SELECT Statement.


Additional Connection Properties Panel
- Click on Add property to add the properties described in the table below:
| Property | Value | Example |
|---|---|---|
| Driver | {MAS 90 4.0 ODBC Driver} | |
| UID | [Sage 100 Username] | |
| PWD | [Sage 100 Password] | |
| Directory | [Sage MAS90 path] | \\[Server]\Sage\Sage 100 Advanced\MAS90 |
| Prefix | [Sage MAS90 path]\SY | \\[Server]\Sage\Sage 100 Advanced\MAS90\SY |
| ViewDLL | [Sage MAS90 path]\Home | \\[Server]\Sage\Sage 100 Advanced\MAS90\Home |
| Company | [Company Code] | ABC |
| LogFile | \PVXODBC.LOG | |
| CacheSize | 4 | |
| DirtyReads | 1 | |
| BurstMode | 1 | |
| StripTrailingSpaces | 1 | |
| SERVER | NotTheServer |
For more information about these settings, click here.
Advanced Settings Panel
- In the Tracking Type drop-down list, select Date.
- Set the time zone to the Sage 100 Application Server Time.
You should have a result similar to this:
- Click on Save to finish.
Importing the Extractions
This feature allows you to import a pre-defined template or to restore a backup that you may have done yourself with the Export feature (refer to Export an Extraction for more details).
Some pre-defined templates are already available; if you don't have access to them, please contact your partner. An example of a pre-defined template you could use is the one which defines the list of tables and fields to be synchronized to send Sage 300, X3, Acumatica, Salesforce data to the Cloud.
An Extraction per Source connection you created is required to retrieve data properly.
- Click on one of the extractions in the list then on the Import icon located on the upper right-hand corner.

- In the Import Extraction window, click on the Choose a zip file hyperlink to browse to the location you saved the export .zip file or drag it directly into that window and click on Next.

For Sage 100, four zip files will be provided.
- If you are doing a consolidation, import the DS_EXTR_[Software-Version]_[Extraction-Version]_Sage 100 with refresh DS-CONSO.zip file.
- If you only have one Company and want to replicate the database, import the DS_EXTR_[Software-Version]_[Extraction-Version]_Sage 100 with refresh DS-SYNC.zip file to perform a synchronization.
- On the left pane, select the type of extraction you want to perform and click on Next.


For Sage 100, it is required to use CPYID for the Column Name and the Company codes for the Unique Identifier field.
- Refer to Setup the Extraction Panel to define the extraction and click on Import to finish the process.


- You should have a result similar to this:

The diagram below illustrates how Data Sync processes data.
The Extractions window will automatically switch to the Tables window.
Refer to Add a SQL Query if you want to add SQL statements to some tables and Setup the Field Section to customize the fields (add calculation, change destination name etc.)
Add SQL Query with ODBC connector without Subqueries
When Subqueries on your Source connection for ODBC are disabled, Nectari Data Sync no longer parses your code with the settings and only executes raw code entered in the SQL Query window. Note that ERPs such as Sage 100
For more information on Sage 100
When adding an SQL Query (refer to Setup the Field Section), there are multiple guidelines to be mindful of:
- If Delimiters are absolutely necessary with your ODBC Driver, you will have to set them.
- To do a Join , your Tables must be placed inside {oj […]}.
SELECT Customer.*
FROM {oj Customer INNER JOIN SalesReps ON Customer.SALESREP = SalesReps.SALESREP}
- You cannot use the * (asterisk) without an Alias in your SELECT statement if your SELECT statement joins more than one Table. While this might not give you an error, there is a risk of introducing errors when you have multiple Columns with the same name across the different Tables .
Here is an example of a statement that would cause errors:
SELECT *
FROM {oj Customer INNER JOIN SalesReps ON Customer.SALESREP = SalesReps.SALESREP}
- You cannot use multiple * (asterisk) with an Alias in your SELECT statement. This issue also applies to multiple Columns with the same name, although this will simply break when performing the Process Deleted Records task, as it will not be able to find which Table the Field comes from.
Here is an example of a statement that would cause errors:
SELECT Customer.*, SalesReps.*
FROM {oj Customer INNER JOIN SalesReps ON Customer.SALESREP = SalesReps.SALESREP}- Avoid creating Calculated Fields in the SELECT statement. Use the menu options in the Field section instead (refer to Setup the Field Section). In most cases, this will not cause a problem. However, when setting that Field as a Primary Key or Tracking Key, there is a risk of introducing an error during the Incremental Load or Process Deleted Records tasks.
If you wish to use Functions, ODBC does not support T-SQL or PL/SQL functions. You need to use ODBC functions available to the driver. Please visit Microsoft’s documentation for more details regarding these Functions.
Adding a Table not included in the Extraction zip file
- Refer to Setup the Field Section to use the following Calculated Field as Tracking Key for Incremental Load task if you wish to add a Table:
The Table (or one of the tables if you have done a Join to get them from another table) must contain the DateUpdated and TimeUpdated fields.
{fn TIMESTAMPADD(SQL_TSI_SECOND,
{fn CONVERT( {fn FLOOR( {fn CONVERT(TimeUpdated,SQL_FLOAT)} * 3600 ) } - {fn CONVERT( {fn FLOOR( {fn CONVERT(TimeUpdated,SQL_FLOAT)} ) }, SQL_INTEGER) } *3600, SQL_INTEGER) },
{fn TIMESTAMPADD(SQL_TSI_HOUR, {fn CONVERT( {fn FLOOR( {fn CONVERT(TimeUpdated,SQL_FLOAT)} ) }, SQL_INTEGER) } ,{fn CONVERT(DateUpdated,SQL_TIMESTAMP)} )} )}
Validating and Building the Extractions
Once your extraction (source, destination connection and their related tables) is set up, the next step is to validate the setting of an extraction, before being able to run it.
The feature will:
- Ensure that all the tables/fields exist in the source connections,
- Validate all SQL queries or calculated fields,
- Ensure that the data integrity in the destination connection is not affected (ex: change the table structure).
To do so:
- Select the extraction you want to validate and build in the list and click on the Validate and Build icon.

- In the new window, choose the action which best fits your needs and click on Build (Validate for Migration and Export extraction types).

The choice will be different accordingly to the extraction type you select.
For Synchronization / Consolidation and extraction types:
For Migration and Export extraction types:

- Wait for the process to be done.
A Validation report window will appear to give you a quick overview on the process once it's finished. The results are displayed in the Status column and if there is an error, you will get more details by clicking on the hyperlink in the Error column which leads to Log Page.
Running the Extractions
Once your data have been validated (refer to Validate and Build an Extraction for more details), you can manually run the extraction if you want an immediate result instead of scheduling it.
- Select the extraction you want to run in the list and click on the Run Extraction Now icon.

- In the upper-right hand corner, choose the action you want to execute and the table(s) then click on Run.


Load (for the Migration extraction type only): Loads all data in your destination from your source.
Truncate and Load: Replaces all data in your destination with the current data from your source.
Incremental Load: Retrieves only records that have changed since your last Incremental Load and replace their corresponding records in your destination with the updated ones.
Process Deleted Records: Maximum quantity of days for the validation process to check if records have been deleted based on the last changed date. i.e. If value is set to 30 days, the system will check all the transactions that were created or updated in the last 30 days and then validate if they still exist in the source. If they don't exist anymore in the source, they will be then deleted from the destination.
- Wait for the process to be done.
When the process is finished, the results are displayed in the Status column. If there is an error, you can view more details on it by clicking on the hyperlink in the Error column, which leads to the Log Page.
Data Source Configuration
Environments and Data Sources
The description given to a Data Source created for the first time is used throughout the environments to describe this specific Data Source.
Give a generic description for the first time (e.g. ERP Data Source, Cube Data Source) and if necessary, rename it after the first environment has been created.
The following information is needed to configure the Data Sources:
- Database server credentials: Server name, Instance, Authentication strategy.
- Main ERP database information: Database and schema name.
ERP Data Source
- In the upper-right hand corner, click on the
 to access the Administration section.
to access the Administration section.
- On the left pane, select Env. & Data Sources.
- By default, there is already an environment called Production,
which you can rename by double-clicking in the name box. Once changed, press the Enter
key.

- In the Data Sources section, click on
 Add to create the first Data Source.
Add to create the first Data Source.
- Complete the ERP Data Source configuration. See instructions for MS SQL Server below.



- Datasource description:
- If you use Data Sync:
- Sage 100 DATASYNC
- If you don't use Data Sync:
- Sage 100 VIEWS
- For UDM Template:
- Sage 100 TABLES
- Type:
- SQLSERVER
- Server:
- Database server of Sage 100
- Database name:
- Name of the Sage 100 database (beware of the case sensitivity)
- Database schema name:
- Create the two following entries by clicking on the icon (replace DatabaseName by the appropriate value):
- If you use Data Sync:
-
- DatabaseName.DestinationSchemaInDataSync
- DatabaseName.NEC_CUSTOM_SCHEMA
- If you don't use Data Sync:
-
- DatabaseName.NEC_CUSTOM_SCHEMA
- DatabaseName.dbo
- For UDM Template:
-
- DatabaseName.dbo
- DatabaseName.NEC_CUSTOM_SCHEMA
-
Note
This second line contains the NectariCustom Schema.
You can use a different one, but we highly recommend following this naming convention:
- Start with NEC
- Use all capitals
- Separate words by an underscore
ImportantChoose a unique Custom Schema name for each Environment.
- Nectari schema:
- Enter the chosen Nectari custom schema for the current environment
- Authentication stategy:
- UseSpecific
- User Name:
- SQL User accessing the Sage 100 database. For example, sa.
- Password:
- The user's password.
- Click on Validate then on Save to complete the configuration of the Data Source.
Cube Data Source
In the same Environment as the ERP Data Source, create a new Data Source for the OLAP Cube.
Complete the Data Source Definition with all the appropriate information.
The screenshot below provides an example of this.
- Server:
- Database server where the Nectari OLAP For SQL Server package is installed.
- Database name:
- NectariCube.
- Database schema name:
- NectariCube.NEC_FOLDER (replace FOLDER by the folder name).
- Where NEC_FOLDER (replace FOLDER by the folder name) is the schema used in the ERP Database of the same environment.
- Nectari schema:
- Enter the chosen custom schema for the current environment
- Click on Validate then on Save.
- Click on Set as Data Warehouse to define the Data Source as a Data Warehouse then enter the following information:
- Database warehouse schema:
- Enter the chosen Nectari custom schema again.
- Use MARS during the cube loading:
- Unchecked
- Click on Validate then on Save.
Refer to Environments and Data Sources for more details about the MARS option .
Importing Templates
For each environment, the following previously configured information will be required:
- ERP Database Name
- Nectari Custom Schema
- ERP Schema
Download the Template file: TPL_9.X.XXX_Sage100Conso.zip.
The X represents the build number of the template (use the highest available).
Running the Import Template
- In the upper-right hand corner, click on the to access the Administration section.
- In the Administration section, click on the
 Templates drop-down menu in the left pane.
Templates drop-down menu in the left pane. - Select
 Import Template.
Import Template. - Choose the specific location where the new templates will be installed and click on Next.
 Note
NoteUsually, the Root folder is used.

- In the Import Template window, click on Select files....

- Find the folder where you saved the Template.zip file in order to select it then click on Open.
- In the Data Sources Mapping screen, associate the Data Sources (ERP) listed in the Received Data Sources Description column (those from the template) with the Data Sources you previously defined in the Central Point (listed in the Current Data Sources Description column)
- In the Received Data Sources Description column, ensure that only the Data Sources checkboxes you want to use from the template are ticked off.
- In the Current Data Sources Description column, click on Bind a Data Source to access the drop-down list containing the existing Data
Sources and click on Next.

In the next screen all of the Templates content is displayed, against what the Central Point already has.
By default, on the first install, everything will be set to Add (leave everything by default) .
- In the case of a first installation, the first four columns will display None and Never Installed,
the next three will detail the Template content, and the last three gives you the choice to
Add, Update or Skip during the installation.Note
In the case of an update, you can refer to Updating template for more details.
- Click on Next (this can take time).


- Once this has been completed, a window will be prompted to input the necessary parameters to create the custom objects.
- If more than one Environment have been created, you will see a column per Environment. You can untick an Environment checkbox, in which case the Global Scripts will not run in it.
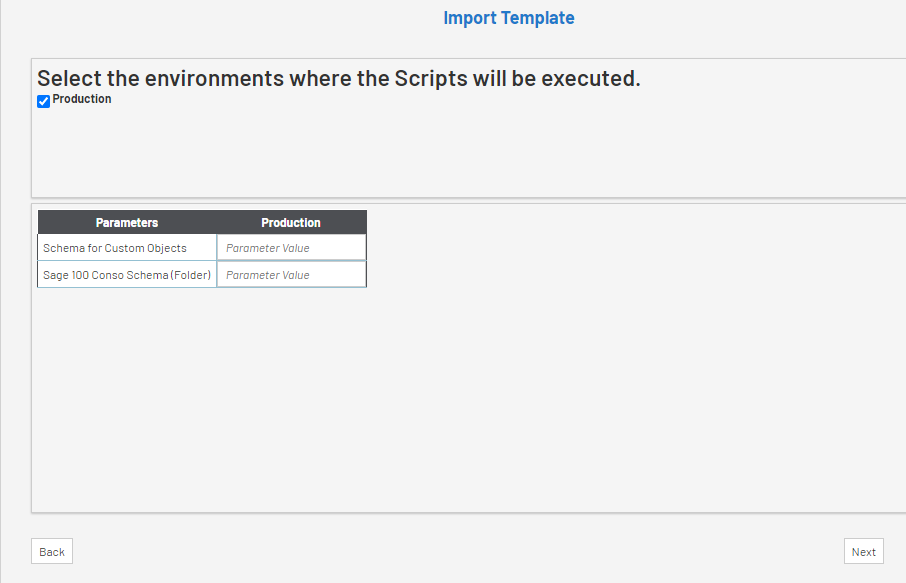
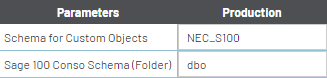
- Complete the parameters, see examples below, and click on Next.
- After importing, an Execution Report will be produced, as shown below.Note
The first section is for the ERP Data Source and the one below it is for the Cube Data Source.
You can click on the
 button to see the details of each script individually. If no failures
are reported, close the window.
button to see the details of each script individually. If no failures
are reported, close the window.

- If any of the scripts failed to run, a fail icon
 will be displayed. Click on the fail symbol to
view the Report Preview window, which shows the respective SQL script.
will be displayed. Click on the fail symbol to
view the Report Preview window, which shows the respective SQL script.
- Copy this script,
debug, and run it separately if needed. Users who are proficient with SQL can debug it
straight in the Report Preview window and run it by clicking on the Try to rerun button.


Updating template
Some considerations you must take into account before starting:
- Making fresh backups of both the Nectari database and Central Point before doing a template update is highly recommended.
- Check the Nectari Data Models and Nectari custom SQL objects that may have been delivered with the initial template version, as you might lose these customizations upon updating.
- You must have a template version that matches the software version installed. If you are using Nectari 9, the template should be also 9.
When performing an upgrade of the Nectari software, it will only update the software and not the template. In other words, the existing Nectari Data Models and Views won't be affected.
After a software upgrade, it is not mandatory to systematically perform a template update. A template update is useful if you have encountered problems with specific Nectari Data Models or Nectari custom SQL objects as it includes fixes.
To update a template:
- After having mapped the Data sources, tick the checkboxes of the objects you want to upgrade and click on Next.
 Note
NoteBy default, no checkbox in the Update column will be ticked. If there is a new Data Model / View the Add checkbox will be ticked. Select Skip if you want to ignore it.
ImportantIf you tick the Update checkbox, it will overwrite the existing Nectari objects associated with that Data Model or connected to the others (dependencies). Please note that if any customizations have been done, they will be lost.

- Select the environment in which the scripts will be executed and click on Next.
- Complete the parameters and click on Next.
- In the Execution report window, If any of the scripts failed to run, a fail icon will be displayed. Click on the fail symbol to
view the Report Preview window, which shows the respective SQL script.
- Copy this script,
debug, and run it separately if needed. Users who are proficient with SQL can debug it
straight in the Report Preview window and run it by clicking on the Try to rerun button.
Building and Loading the OLAP Cubes
To create the Cubes database structure in the NectariCube database previously installed, you need to Build the Cube.
- In the upper right-hand corner, click on the to access the Administration section.
- In the left pane, click on
 OLAP Manager.
OLAP Manager. - In the right pane, click on
 Manage.
Manage.
- In the left section, select all the Cubes to build by ticking the checkbox next to the Description column.
- In the Manage window, select Build in the Action drop-down list then the environment(s) and click Confirm.

- In the Confirmation window, tick the checkbox and click on Yes.

- If errors occur refer to Logs to activate the logging feature.



Now that the Cubes are built, you can now populate them.
- In the right pane, click on Manage.
- In the left section, select all the Cubes to load by ticking the checkbox next to the Description column.
- In the Manage window, select Load All in the Action drop-down list then the environment(s) and click Confirm.

- In the Confirmation window, tick the checkbox and click on Yes.

The template installation is now complete.
Regular data refresh jobs for the Cubes can now be scheduled. For more details on how to do this, refer to Scheduler.
Populate Zip Codes
During the import, a table is created in the Nectari Custom Schema for ZIP codes.
Although the ZIP table is not required for the Sage 100 Template to function, downloading and populating the ZIP table with a recent data dump of ZIP codes including the (latitude, longitude) details is recommended.
Web Browsers have updated their policy regarding Cookies and these changes must be applied to your Web Client if you want Nectari embedded into your ERP website, or use Single Sign-On (SSO). Refer to Cookie Management for more details.